
Deep Learning Weekly: Issue #207
Facebook’s open-source chat bot that builds long-term memory, Google’s new approach to image synthesis using diffusion models, a paper on multimodal representation for neural code search, and more

Hey folks,
This week in deep learning, we bring you Facebook's open-source chat bot that builds long-term memory and searches the internet, an AI-powered grocery experience, a curated benchmark for distribution shifts and Google's novel approach to image synthesis using diffusion models.
You may also enjoy Samsung's robot vacuum with world-class object recognition, AI voice actors that sound more human than ever, a paper on multimodal representation for neural code search, a paper on searching for object detection architectures for mobile accelerators, and more!
As always, happy reading and hacking. If you have something you think should be in next week’s issue, find us on Twitter: @dl_weekly.
Until next week!
Industry
Blender Bot 2.0: An open source chatbot that builds long-term memory and searches the internet
Facebook AI Research built BlenderBot 2.0, the first chatbot that can simultaneously build long-term memory it can continually access, search the internet for timely information, and have sophisticated conversations on nearly any topic
Pioneers of deep learning think its future is gonna be lit
Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, explain the current challenges of deep learning and what the future might hold.
AI voice actors sound more human than ever—and they’re ready to hire
A Seattle-based startup that offers AI voices for corporate e-learning videos and other areas.
New starter kits make it easier to create your model as a microservice, deploy on RedHat OpenShift, and generally get your machine learning apps to production in a cloud-native environment.
Hungryroot delivers AI-powered grocery experience
Hungryroot, a delivery service that makes use of collaborative filtering, hopes to be the Netflix equivalent for online groceries in the United States.
Mobile & Edge
Training a Tiny Pix2Pix GAN for Snapchat
Cat Face is the latest SnapML-powered Lens built by the team at Fritz AI, performing image-to-image translation to transform outlines of cat faces into realistic cats with a model 95% smaller than Pix2Pix.

Samsung Raises the Bar for Smart Robot Vacuums With the Jet Bot AI+
Samsung announces the launch of Jet Bot AI+, the world’s first robot vacuum that comes equipped with a 3D active stereo-type sensor and world-class object recognition.
VoiceTurn is a voice-controlled turn signal system for safer bike rides
A comprehensive tutorial on setting up VoiceTurn using an Arduino Nano 33 BLE Sense and Edge Impulse.
Real-World ML with Coral: Manufacturing
A technical introduction to the manufacturing use-cases of Coral Edge TPU, a complete platform for accelerating neural networks on embedded devices.
On-Demand Session: Deploying Highly Accurate Retail Applications Using a Digital Twin
A brief blog on the use of some synthetic data, a digital twin, and the Fleet Command, a hybrid-cloud platform for deploying and managing AI models at the edge.
Learning
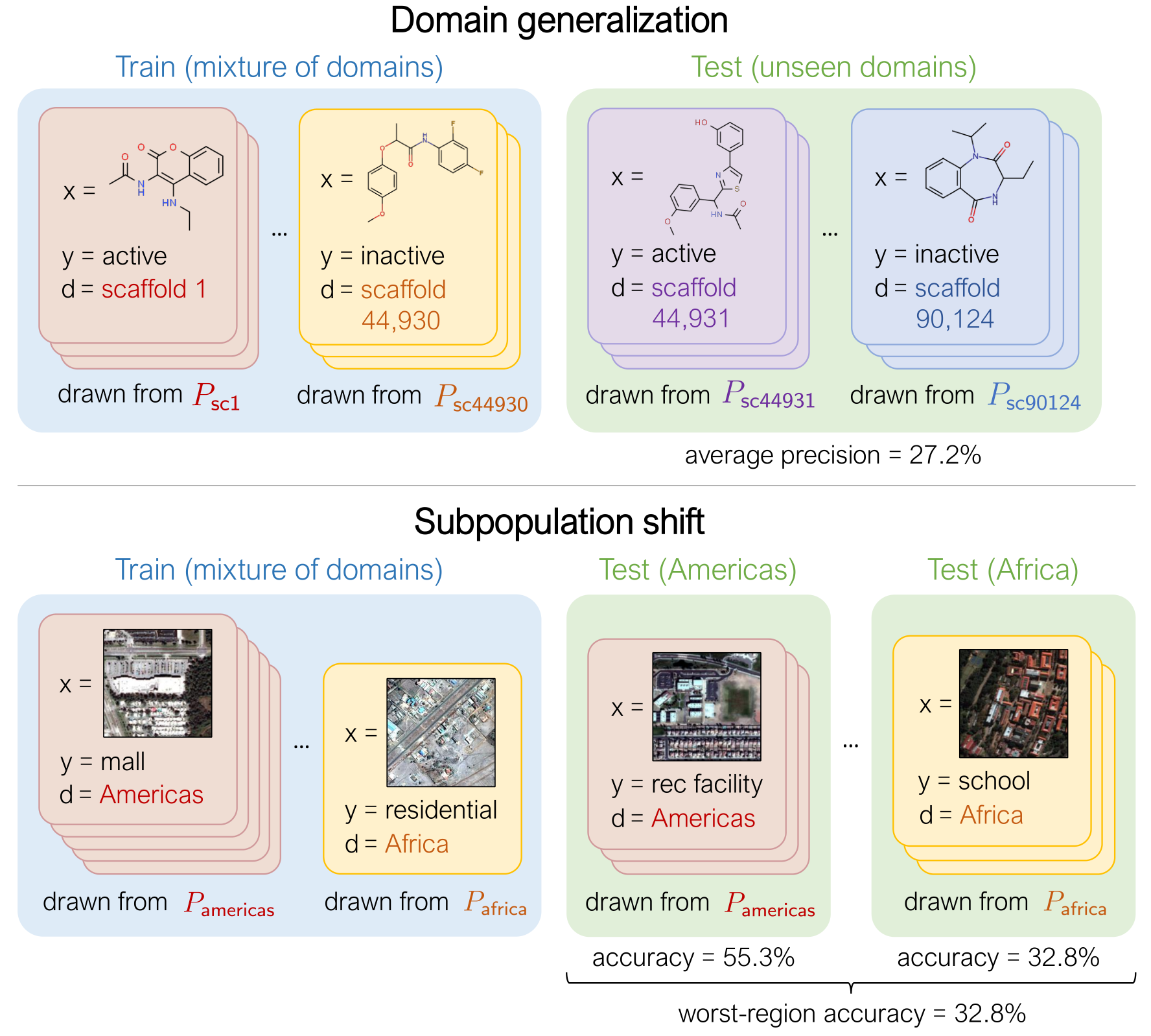
WILDS: A Benchmark of in-the-Wild Distribution Shifts
WILDS, a curated benchmark of 10 datasets that reflect natural distribution shifts arising from different cameras, hospitals, molecular scaffolds, experiments, demographics, countries, time periods, users, and codebases.
High Fidelity Image Generation Using Diffusion Models
Google presents two connected approaches that push the boundaries of the image synthesis quality for diffusion models — Super-Resolution via Repeated Refinements (SR3) and a model for class-conditioned synthesis, called Cascaded Diffusion Models (CDM).
Hand Labeling Considered Harmful – O'Reilly
A comprehensive article detailing the inefficiencies of labeling data by hand.
Deep Learning over the Internet: Training Language Models Collaboratively
A blog that thoroughly describes a new method for collaborative distributed training that can adapt itself to the network and hardware constraints of participants.
Libraries & Code
The Netflix Data Explorer tool allows users to explore data stored in several popular datastores (currently Cassandra, Dynomite, and Redis).
Marak/faker.js: Generate massive amounts of data
A library for generating massive amounts of fake data on the browser and on Node.js.
A framework to simplify the integration, scaling and acceleration of complex multi-step analytics and machine learning pipelines on the cloud.
Papers & Publications
Multimodal Representation for Neural Code Search
Abstract:
Semantic code search is about finding semantically relevant code snippets for a given natural language query. In the state-of-the-art approaches, the semantic similarity between code and query is quantified as the distance of their representation in the shared vector space. In this paper, to improve the vector space, we introduce tree-serialization methods on a simplified form of AST and build the multimodal representation for the code data. We conduct extensive experiments using a single corpus that is large-scale and multi-language: CodeSearchNet. Our results show that both our tree-serialized representations and multimodal learning model improve the performance of neural code search. Last, we define two intuitive quantification metrics oriented to the completeness of semantic and syntactic information of the code data.
CoBERL: Contrastive BERT for Reinforcement Learning
Abstract:
Many reinforcement learning (RL) agents require a large amount of experience to solve tasks. We propose Contrastive BERT for RL (CoBERL), an agent that combines a new contrastive loss and a hybrid LSTM-transformer architecture to tackle the challenge of improving data efficiency. CoBERL enables efficient, robust learning from pixels across a wide range of domains. We use bidirectional masked prediction in combination with a generalization of recent contrastive methods to learn better representations for transformers in RL, without the need of hand engineered data augmentations. We find that CoBERL consistently improves performance across the full Atari suite, a set of control tasks and a challenging 3D environment.
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Abstract:
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we investigate the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We discover that regular convolutions are a potent component to boost the latency-accuracy trade-off for object detection on accelerators, provided that they are placed strategically in the network via neural architecture search. By incorporating regular convolutions in the search space and directly optimizing the network architectures for object detection, we obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on Google EdgeTPU, 3.4 mAP on Qualcomm Hexagon DSP and 2.7 mAP on Nvidia Jetson GPU without increasing latency. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2x speedup.