


Deep Learning Weekly: Issue #222
PyTorch 1.10, Apple and Google’s new chips, MT-NLG and OpenPrompt
Hey folks,
This week in deep learning, we bring you Kaggle’s Data Science survey, Clarifai’s fundraising round, a history of the AI field, and a nice introduction to neural networks.
You may also enjoy practical tricks to train deep learning models, a paper on Quantum NLP, MT-NLG model for language generation, and more!
As always, happy reading and hacking. If you have something you think should be in next week's issue, find us on Twitter: @dl_weekly.
Until next week!
Industry
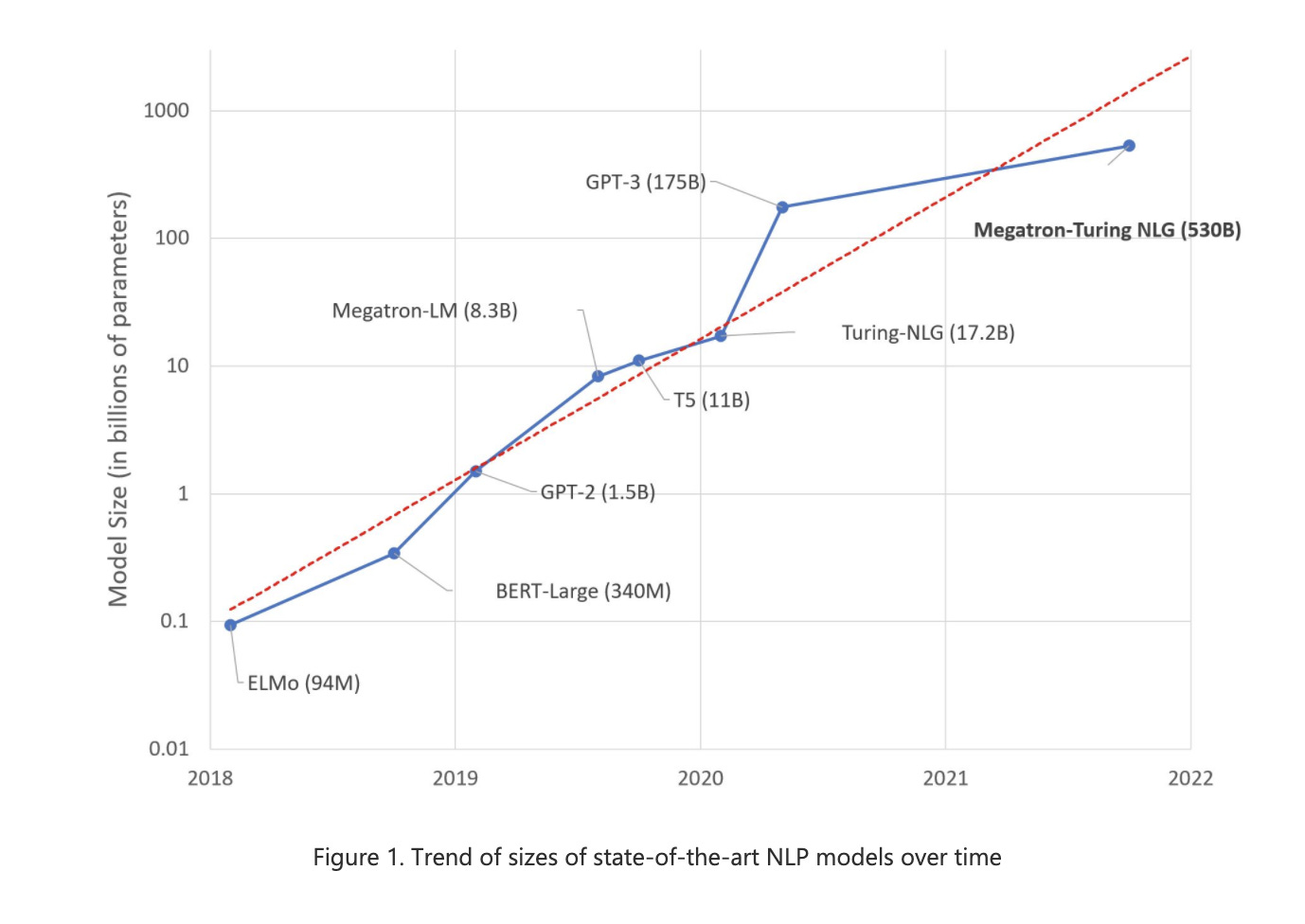
Using DeepSpeed and Megatron to Train the World’s Largest Generative Language Model
Microsoft Research introduces MT-NLG, the largest and most powerful transformer language model trained to date, with 530 billion parameters. It is the result of a research collaboration between Microsoft and NVIDIA.
‘Small Data’ Are Also Crucial for Machine Learning
This article emphasizes the importance of approaches enabling the creation of AI systems based on small datasets. Acknowledging the success of techniques like transfer learning can help foster innovation in new, interesting directions.
To Software 2.0 And Beyond: Celebrating Our Series C Funding
Clarifai, the AI platform with over 100,000 global users, announced a $60 million fundraising round. Clarifai will announce a suite of exciting new products and plans to double the size of the team in the next year.
Americans Need a Bill of Rights for an AI-Powered World
The White House Office of Science and Technology Policy will be developing a bill of rights, working with experts across the federal government, in academia, civil society, and the private sector to ensure that data-driven technologies reflect and respect democratic values.
The Turbulent Past and Uncertain Future of Artificial Intelligence
The author of this article reminds us of the ups and downs the AI field has known since the term was introduced in 1956, and details what it could mean for the evolution of the field in the coming decades.
Mobile & Edge
Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built
Apple released the new chips powering the new MacBook Pro: M1 Pro and M1 Max. They achieve impressive performance for machine learning computations, while ensuring industry-leading power efficiency.
Announcing the Winners of the TensorFlow Lite for Microcontrollers Challenge!
The TensorFlow team announced the 5 winners of its TensorFlow Lite for Microcontrollers challenge. The winning projects are diverse, from a squat counter to a device embedded in your pillow to monitor snoring.
With Tensor, Google bets on its own chip design for the Pixel 6
Google now offers a phone that is powered by Tensor, a chip of its own design specifically optimized for AI/ML applications, unlocking amazing new experiences that require state of the art ML.
Learning
Self-Supervised Learning Advances Medical Image Classification
Google AI presents a new strategy to improve medical image classification, based on self-supervised pre-training on unlabeled natural and medical images, and find that it can significantly improve upon existing strategies.

Machine learning is not nonparametric statistics
This post emphasizes the fundamental differences between Machine Learning and Statistics. In particular, when doing statistics, model complexity must be explicitly constrained in order to extrapolate to new data—which does not seem to be the case when doing ML.
ML Project: End-to-End Fraud Detection with Comet
Comet Data Scientist Harpreet Sahota with a comprehensive guide for building an end-to-end fraud detection system, exploring the specifics of how to work with imbalanced classification problems. Colab notebooks for each part of the project are included in the post.
How to Train Large Deep Learning Models as a Startup
This post from Assembly AI shares very useful insights for anyone who wants to train large deep learning models with a tight budget and who needs to iterate quickly.
Neural Networks (from scratch)
A very nice interactive tool to understand in-depth what a neural network is and how it is trained, introducing all the needed concepts like activation function, loss or backpropagation.
Composability in Julia: Implementing Deep Equilibrium Models via Neural ODEs
This post explains the link existing between Deep Equilibrium Models and Ordinary Differential Equations, and uses it to implement nonlinear solvers with neural networks in Julia.
Libraries & Code
OpenPrompt: An Open-Source Framework for Prompt-learning
This library provides a framework to deploy prompt-learning, a recent paradigm to adapt pre-trained language models to NLP tasks, which consists of modifying the input text to match one of the pre-trained tasks.
2021 Kaggle Machine Learning & Data Science Survey
Kaggle released the 25,973 responses collected through an industry-wide survey that presents a truly comprehensive view of the state of data science and machine learning. They published an informative executive summary as well.
PyTorch 1.10 Release, including CUDA Graphs APIs, Frontend and Compiler Improvements
PyTorch 1.10 has been released, with over 3,400 commits by 426 contributors since 1.0. Updates are focused on improving training, performance, and developer usability.
Papers & Publications
A Few More Examples May Be Worth Billions of Parameters
Abstract
We investigate the dynamics of increasing the number of model parameters versus the number of labeled examples across a wide variety of tasks. Our exploration reveals that while scaling parameters consistently yields performance improvements, the contribution of additional examples highly depends on the task's format. Specifically, in open question answering tasks, enlarging the training set does not improve performance. In contrast, classification, extractive question answering, and multiple choice tasks benefit so much from additional examples that collecting a few hundred examples is often "worth" billions of parameters. We hypothesize that unlike open question answering, which involves recalling specific information, solving strategies for tasks with a more restricted output space transfer across examples, and can therefore be learned with small amounts of labeled data.
The Dawn of Quantum Natural Language Processing
Abstract
In this paper, we discuss the initial attempts at boosting understanding human language based on deep-learning models with quantum computing. We successfully train a quantum-enhanced Long Short-Term Memory network to perform the parts-of-speech tagging task via numerical simulations. Moreover, a quantum-enhanced Transformer is proposed to perform the sentiment analysis based on the existing dataset.
|