
Deep Learning Weekly: Issue #228
PyTorch Live, DAIR, Gopher, NeurIPS 2021, RLDS, Clearview AI, and more
Hey folks,
This week in deep learning, we bring you AI to help mathematicians, a large-scale microscopy images dataset, NeurIPS 2021 Highlight, and a new AI research institute.
You may also enjoy self-driving taxis in Beijing, Axiado’s funding round, PyTorch Live, and more!
As always, happy reading and hacking. If you have something you think should be in next week's issue, find us on Twitter: @dl_weekly.
Until next week!
Industry
After being pushed out of Google, Timnit Gebru forms her own AI research institute: DAIR
Timnit Gebru, a former leader of Google’s ethics in AI team, is now setting up a brand new research institute, DAIR, set to counter Big Tech’s influence on the research, development and deployment of AI.
Biden administration again looks to increase AI R&D funding at civilian agencies
The Biden administration has proclaimed the need to advance American leadership for generations to come, and requested $1.7 billion in funding for AI research and development at civilian agencies.
Baidu, Pony AI granted China’s first licenses to charge passengers for self-driving taxis in Beijing
The two companies have been given the green light to start charging passengers to use their autonomous taxis in Beijing, with a plan to scale the service rapidly. These are the first such licenses delivered in the country.

NVIDIA AI Enterprise Helps Researchers, Hospitals Targeting Cancer Hit the Mark
The Netherlands Cancer Institute (NKI) and other health tech companies announced they are using the NVIDIA AI Enterprise software suite to test AI workloads on higher-precision 3D cancer scans than are commonly used today.
Clearview AI is closer to getting a US patent for its facial recognition technology
Clearview AI has built a facial recognition technology based on images of people that it scrapes across the internet. The company’s patent application details its use of a “web crawler” to acquire images.
Mobile & Edge
AI Chip Startup Axiado Closes Another Funding Round
Silicon Valley-based Axiado has closed a series B funding round totaling $25 million. Axiado is developing hardware and AI models for network security and attack detection.
PyTorch released PyTorch Live, a set of tools designed to make AI-powered experiences for mobile devices easier. PyTorch Live offers a single programming language (JavaScript) to build apps for Android and iOS.
Tiny machine learning design alleviates a bottleneck in memory usage on IoT devices
A research team composed of researchers from various labs including the MIT-IBM Watson AI Lab and Samsung has designed a new technique to shrink the amount of memory needed by ML models to run on IoT devices.
Learning
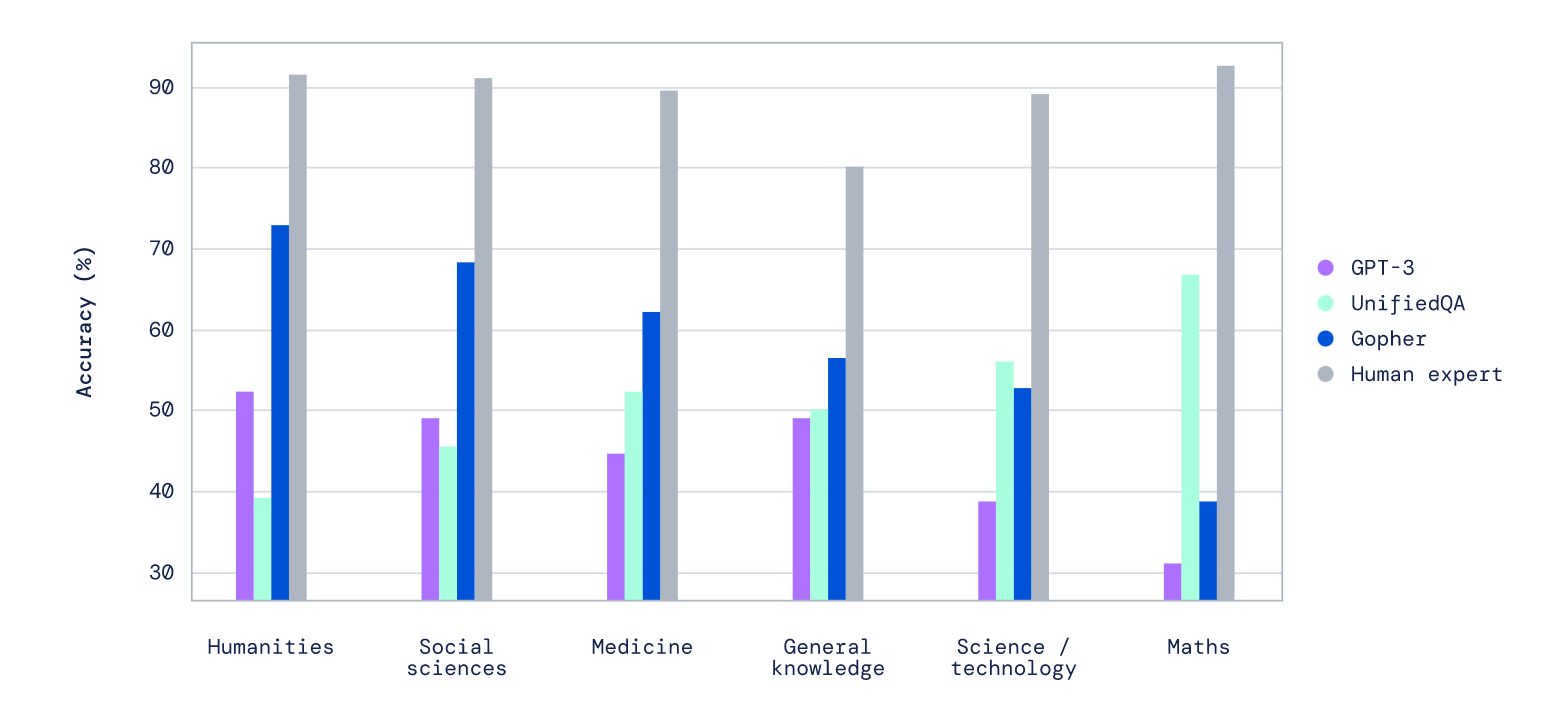
Language Modelling at Scale: Gopher, Ethical considerations, and Retrieval
DeepMind released three papers offering a foundation for DeepMind’s language research going forward: a study of a 280 billion parameter transformer language model, a study of ethical and social risks associated with it, and a paper investigating a new architecture.
Neural-Control Family: What Deep Learning + Control Enables in the Real World
This post presents deep-learning-based control methods, which enable autonomous systems to not only achieve exciting new capabilities and better performance than classic methods, but also enjoy formal guarantees for safety and robustness.
Exploring the beauty of pure mathematics in novel ways
DeepMind’s team has discovered an unexpected connection between different areas of mathematics using ML. These are the first significant mathematical discoveries made with ML.
Masked image modeling with Autoencoders
This Keras tutorial describes a technique to pretrain large vision models inspired from the pretrained algorithm of BERT. The idea is to mask patches of an image and to predict the masked patches through an autoencoder.
Paper Digest: NeurIPS 2021 Highlights
NeurIPS 2021 Highlights is out, showing the 2000+ papers published at NeurIPS 2021. It enables users to filter out papers using keywords and to find related papers.
NeurIPS 2021—10 papers you shouldn’t miss
This recap of NeurIPS 2021 from the team at Zeta Alpha is a bit more focused—it zooms in on 10 different papers from this year’s conference that you won’t want to miss.
Libraries & Code
RLDS: An Ecosystem to Generate, Share, and Use Datasets in Reinforcement Learning
Google Research released Reinforcement Learning Datasets (RLDS), a suite of tools for recording, replaying, manipulating, annotating and sharing data for sequential decision making.
CytoImageNet (CytoImageNet: A large-scale pretraining dataset for bioimage transfer learning)
CytoImageNet is a large-scale dataset of 890k microscopy images (894 classes), constructed from 40 openly available microscopy datasets. Its primary purpose is to be used for pretraining as a pretext task for learning useful bioimage representations.
Papers & Publications
A Survey of Generalisation in Deep Reinforcement Learning
Abstract
The study of generalisation in deep Reinforcement Learning (RL) aims to produce RL algorithms whose policies generalise well to novel unseen situations at deployment time, avoiding overfitting to their training environments. Tackling this is vital if we are to deploy reinforcement learning algorithms in real world scenarios, where the environment will be diverse, dynamic and unpredictable. This survey is an overview of this nascent field. We provide a unifying formalism and terminology for discussing different generalisation problems, building upon previous works. We go on to categorise existing benchmarks for generalisation, as well as current methods for tackling the generalisation problem. Finally, we provide a critical discussion of the current state of the field, including recommendations for future work. Among other conclusions, we argue that taking a purely procedural content generation approach to benchmark design is not conducive to progress in generalisation, we suggest fast online adaptation and tackling RL-specific problems as some areas for future work on methods for generalisation, and we recommend building benchmarks in underexplored problem settings such as offline RL generalisation and reward-function variation.
Advancing mathematics by guiding human intuition with AI
Abstract
The practice of mathematics involves discovering patterns and using these to formulate and prove conjectures, resulting in theorems. Since the 1960s, mathematicians have used computers to assist in the discovery of patterns and formulation of conjectures1, most famously in the Birch and Swinnerton-Dyer conjecture2, a Millennium Prize Problem3. Here we provide examples of new fundamental results in pure mathematics that have been discovered with the assistance of machine learning—demonstrating a method by which machine learning can aid mathematicians in discovering new conjectures and theorems. We propose a process of using machine learning to discover potential patterns and relations between mathematical objects, understanding them with attribution techniques and using these observations to guide intuition and propose conjectures. We outline this machine-learning-guided framework and demonstrate its successful application to current research questions in distinct areas of pure mathematics, in each case showing how it led to meaningful mathematical contributions on important open problems: a new connection between the algebraic and geometric structure of knots, and a candidate algorithm predicted by the combinatorial invariance conjecture for symmetric groups4. Our work may serve as a model for collaboration between the fields of mathematics and artificial intelligence (AI) that can achieve surprising results by leveraging the respective strengths of mathematicians and machine learning.
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Abstract
This paper presents a unified multimodal pre-trained model called NÜWA that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks. To cover language, image, and video at the same time for different scenarios, a 3D transformer encoder-decoder framework is designed, which can not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively. A 3D Nearby Attention (3DNA) mechanism is also proposed to consider the nature of the visual data and reduce the computational complexity. We evaluate NÜWA on 8 downstream tasks. Compared to several strong baselines, NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipulation tasks.